 HiPEAC Vision
HiPEAC VisionThe end of Dennard scaling is leading to a Cambrian explosion of specialized hardware, with better performance and energy efficiency, and optimized non-functional requirements. But it comes at the cost of programming complexity, difficulty in code reuse, and vendor lock-in.
Here to stay: specialized and heterogeneous computing
by Jaume Abella, Leonidas Kosmidis, Thomas Hoberg and Paul Carpenter
Until the early 2000s, while specialized approaches could always improve performance and/or energy efficiency, general-purpose processors had lower cost due to much higher volumes, as well as being more flexible and easier to use. Any niche special purpose chip was soon overtaken by the relentless advance of Moore’s law and Dennard scaling. There was space for a small number of architectures: general purpose CPUs in PC and Macs (x86) and phones (Arm), graphics processing units (GPUs) for gaming and the film industry, and digital signal processors (DSPs) for audio, video and communications.
The release of Intel’s first multi-core CPU in 2005, following the failure of its planned 10 GHz Tejas CPU, was a major change in direction for Intel and a significant milestone in the industry. For the next few years, much of the improved performance came from greater numbers of cores, but this was curtailed by limits on how much software can benefit from parallelism (Amdahl’s Law), as well as practical constraints on the scaling of shared hardware structures.
In 2007, Nvidia released its first CUDA-capable GPU, having realized that its highly multi-threaded architecture, originally developed for 3D graphics rendering, could deliver improved performance for many other data-intensive compute tasks. The downside was that the key computational kernels and supporting code needed to use Nvidia’s new CUDA programming model, which exposed the key characteristics of GPU architecture to the programmer. Since GPUs delivered so much more performance than CPUs, many applications were adapted to use CUDA, spurred by significant investment from Nvidia and heightened interest in the community. These applications employ CUDA where it makes sense, while still using CPUs for the rest of the application. Examples that benefit include desktop image and video processing, high performance computing and artificial intelligence.
In the seventeen years since then, the rise of specialized and heterogeneous architectures is well known. Microsoft started using FPGAs for search. Amazon, Meta and Google have developed specialized chips for their applications. All top ten supercomputers except one have GPU accelerators. There are now hundreds of startups with AI chips. There is still an insatiable demand for more performance, due to the demands of the new computing paradigm, autonomous driving, LLM training and other applications. Meanwhile, the rise of open source hardware has greatly lowered the barrier to entry for the development of custom hardware (see article). Modularity theory (Carliss Y. Baldwin and Kim B. Clark) predicts that as competitive environments mature and technology becomes good enough, the performance advantages of specialized and integrated systems eventually lose ground to the cost and compatibility advantages of a modular and standardized approach. But there are no signs that this is likely to happen again for computing systems in the foreseeable future. Computing systems are likely to be diverse and complex for some time to come.
Key insights
Hardware that is specialized to the application can achieve higher efficiency, e.g., performance-per-watt or joules-per-operation, compared with a general-purpose architecture.
For the foreseeable future, future computing systems will continue to be heterogeneous, driven by application needs and the end of Dennard scaling, and disruptive technologies (e.g., processing-in-memory, quantum computing, and neuromorphic).
Programmability and software portability are of critical importance. There is as yet no performance portable programming environment that allows a single source codebase to achieve good performance across a range of architectures. There may never be one, but more progress towards this goal is needed.
Heterogeneity affects all levels of the software stack: system architecture, operating system, middleware, applications.
Heterogeneous architectures increase complexity, making performance analysis, correctness testing and debugging very difficult. Errors in the developer’s source code may lead to obscure low-level errors in unfamiliar libraries. Similarly a seemingly trivial change may lead to a dramatic difference in performance, for obscure reasons.
Independent application developers are reluctant to adopt niche programming environments unless the advantages are overwhelming. This leads to a “survival of the biggest”: CUDA, OpenMP, etc. New programming approaches should be standardized to drive adoption.
If architectural diversity reduces investment and evolution of general purpose CPUs, more and more workloads may need to move to the cloud to get access to the right accelerators.
Vertical integration risks increasing the market dominance of the largest technology companies, none of which are European.
Key recommendations
Embedded hardware acceleration must be aware of user requirements and software limitations, e.g., accuracy, time-to-solution deadlines (inference speed) and maximum power consumption.
Specialized hardware should be optimized for application semantic precision rather than bit-level precision, trading off arithmetic precision, operation accuracy or approximation, voltage scaling, reliability and others.
Vendor lock-in should be prevented, especially since the vendors are not European.
Interoperability and composability of hardware and software needs to be maintained.
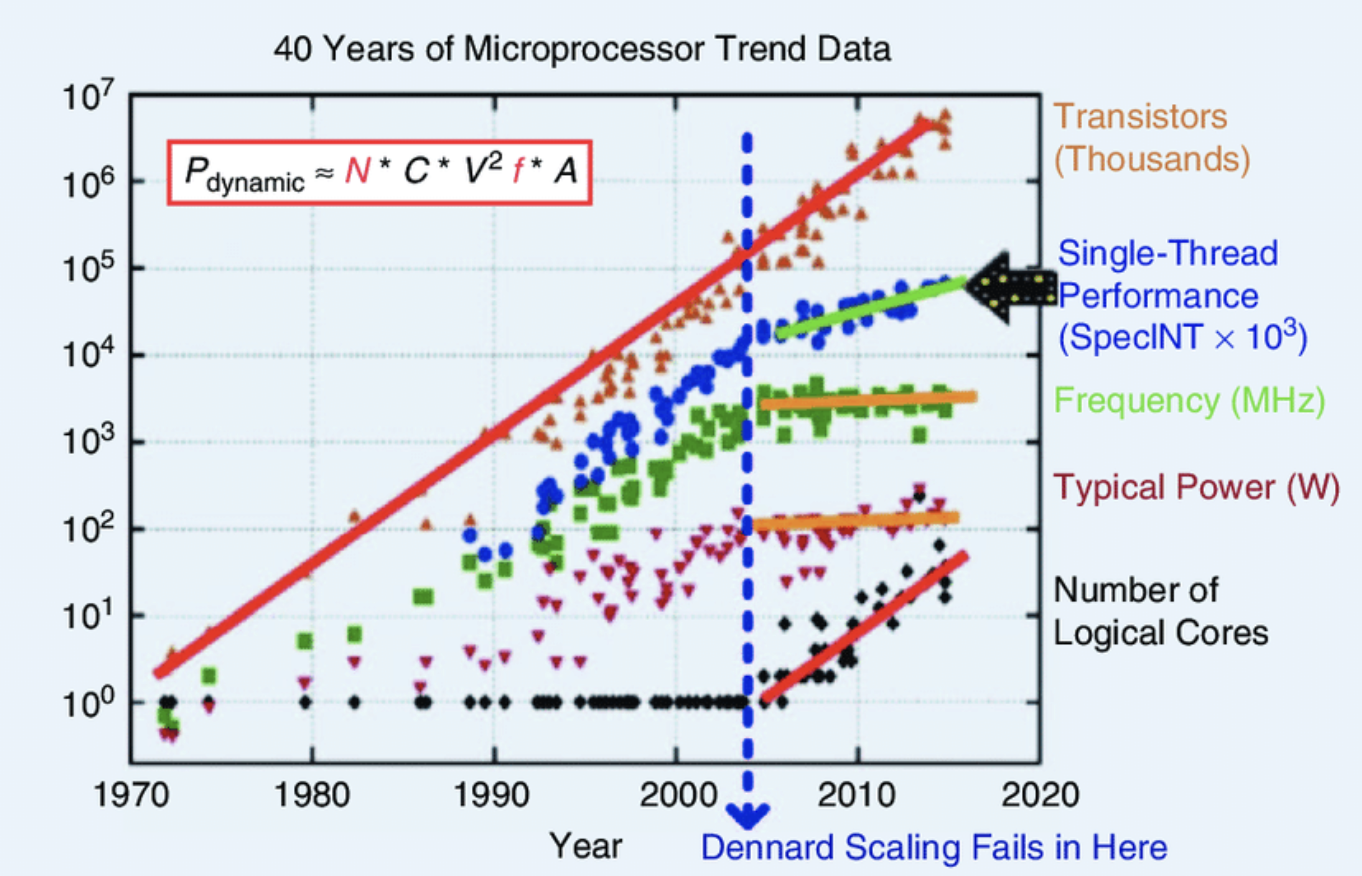 Figure 1 Moore’s law continues to deliver increasing numbers of transistors, but Dennard scaling failed in the early 2000s. The consequences include greater numbers of cores. The plot was originally collected in 2010 for Horowitz et al, and variants have appeared in hundreds of papers and articles.
Figure 1 Moore’s law continues to deliver increasing numbers of transistors, but Dennard scaling failed in the early 2000s. The consequences include greater numbers of cores. The plot was originally collected in 2010 for Horowitz et al, and variants have appeared in hundreds of papers and articles.
Survey of specialization and heterogeneity
Here we outline the main kinds of specialization and heterogeneity:
Graphics Processing Units (GPUs) are the most well-known type of accelerator and are specialized to handle highly parallel tasks. Unlike traditional CPUs that are designed to perform a wide range of computing tasks, GPUs are adapted for concurrency, making them exceptionally efficient for graphics rendering and data-heavy tasks in fields like scientific computing, machine learning, and video processing. The architecture of a GPU is tailored for multi-threading, achieved by housing hundreds or thousands of smaller and more efficient cores. Additionally, GPUs are equipped with high-bandwidth memory, which allows for faster data transfer rates, enabling them to swiftly handle large datasets and complex calculations.
Nvidia GPUs are commonly programmed using CUDA, a parallel computing platform and programming model developed by Nvidia. CUDA allows developers to write software that can take full advantage of the unique architecture, by offering direct access to the GPU's virtual instruction set and parallel computational elements, enabling highly efficient processing for complex computational problems. However, CUDA is proprietary and exclusive to Nvidia GPUs. This exclusivity means that while CUDA is powerful, mature and widely used, it isn't compatible with GPUs from other manufacturers like AMD or Intel. Another example is AMD's ROCm (Radeon Open Compute), an open-source platform designed specifically for AMD GPUs. In order to avoid fragmentation and enable interoperability, Khronos introduced open APIs such as OpenCL and Vulkan, which are lower level than CUDA and therefore allow for more control in expense of programmability, as well as a higher level C++ based solution, SYCL. All major GPU vendors participate in Khronos and co-operate in the definition and standardization of its APis.
Neural Processing Engines (NPEs) are specialized hardware designed to efficiently handle the computations required for neural networks, which are at the core of modern artificial intelligence, image and machine learning applications. Unlike general-purpose CPUs, NPEs are optimized for the parallel processing and matrix operations that are prevalent in deep learning tasks, offering faster performance and greater energy efficiency for AI computations. Like GPUs, they usually have a high number of processing cores and high-bandwidth memory interfaces, but their architecture is tailored for tasks like convolution and matrix multiplication, including at reduced precision.
Programming these engines is usually done using high-level frameworks and libraries tailored to AI and ML, such as TensorFlow, PyTorch, or Keras. These frameworks abstract the complexity of directly programming the hardware, allowing developers to focus on designing and training neural networks using high-level, pythonic interfaces. Underneath these frameworks, lower-level libraries and drivers specifically optimized for NPEs translate these high-level instructions into efficient hardware operations. Additionally, some NPEs support automatic optimization where the engine itself can dynamically adjust computing resources based on the workload, making them highly efficient for varying AI tasks. This combination of specialized hardware and sophisticated software stacks makes NPEs a cornerstone in advancing AI and ML technologies.
Field Programmable Gate Arrays (FPGAs) were introduced by Xilinx in 1985, aimed at rapid prototyping and the implementation of custom digital logic in low-volume applications. They were first recognised as compute accelerators in the 2000s, and there was a significant expansion in the late 2010s, partly spurred by Microsoft’s Catapult project, which employed FPGAs to accelerate web search and real-time AI. In 2024, FPGAs are still a niche device for several reasons. First, FPGAs have a spatial architecture, which is unfamiliar to software developers, since the algorithm is laid out in space in the same way as hardware. High-level Synthesis (HLS) greatly improves matters, since software developers can use extensions of familiar programming languages such as C and C++, but specific annotations and custom control of data transfers are required. Second, the mapping of an algorithm to the hardware depends on the FPGA size and its numbers of resources across multiple dimensions (number of logic cells, DSP slices, amount of embedded SRAM, number of QSFP+ ports, etc.). If the design doesn’t fit, then it doesn’t compile. Thirdly, the software ecosystem for FPGAs is still relatively immature and varies significantly between the two major U.S.-based vendors. Moreover, achieving performance that matches or exceeds that of GPUs or more specialized accelerators is a complex and challenging task.
Vector Processing Units (VPUs) have been used for decades in order to provide high performance processing. First employed by the ILLIAC IV supercomputer in the 1960s, vector architectures were the fundamental design of all later supercomputers. Vector processing comes in many different variants ranging from very long vectors to short Single Instruction Multiple Data (SIMD) units. A vector processing unit can be either tightly integrated in an in-order, out-of-order and/or multithreaded processor or operated as a decoupled accelerator such as a GPU. Moreover, it can operate on a distinct register file or reuse existing register files, a concept known as SWAR (SIMD within a Register) or packed SIMD. Different design choices provide different tradeoffs in terms of area, performance and latency. Thanks to Moore’s Law, in the 1990s vector processing units found their way into general purpose processors in the form of SIMD instructions, mainly for the acceleration of graphics and multimedia tasks. Naturally, embedded processors followed, and with the passing of the years processor designers included longer and longer vector lanes and registers. In the last decade, vector length agnostic ISAs were proposed, first by Arm and later by the RISC-V foundation, allowing software portability among architectures with different vector lane width. Moreover, significant progress has been performed in vectorising compilers but not all compiler backends have the same maturity. Consequently, still there is no performance portability among the continuum of vector architectures, and therefore more research on high-level languages is required. Similar to the rest of the hardware technologies, most of the vector processors nowadays are not European. Within the European Processor Initiative (EPI), significant advances have been made with the design of several vector processing units which explore the strengths and the weaknesses of each of their design choices.
Video coding chips, also known as video encoding or transcoding processors, are specialized hardware used by companies like Google YouTube and other streaming service providers to efficiently process and stream video content. 500 hours of content is uploaded to YouTube each minute, and this needs transcoding to every viewable resolution in H264; popular videos are also transcoded using a more complex but more space-efficient codec such as VP9.
Neuromorphic Computing (NMC) was first developed by Carver Mead in the late 1980s. It describes the use of large-scale adaptive analog systems to mimic the human nervous system. Originally, the approach was to use elementary physical components of integrated electronic devices (transistors, capacitors, …) as computational primitives. In recent times, the term neuromorphic has also been used to describe analog, digital, and mixed-mode analog/digital hardware and software systems that transfer aspects of structure and function from biological substrates to electronic circuits (for perception, motor control, or multisensory integration). Today, the majority of NMC implementations are based on CMOS technology. Interesting alternatives are, for example, oxide-based memristors, spintronics, or nanotubes.
Memory systems The basic architecture of a stored program computer still follows the von Neumann architecture outlined in 1945. Commodity memory is built in high volume and generally optimized for increasing capacities not speed. In 1995, Wulf and McKee coined the term “memory wall”, pointing out that there is a limit on how much caches can mitigate the growing gap between processor and memory speeds. Recently, a number of new device types (PCM, STT-RAM, etc.) and memory interfaces (HMC, HBM) have started to offer diverse tradeoffs among capacity, latency, bandwidth, volatility and energy consumption. A traditional memory hierarchy (registers, cache, DRAM and disk) is making way to a collection of memory devices on an equal ranking. This is facilitated by the advent of Compute Express Link (CXL), which promises exciting times for memory systems through a standardized high-bandwidth and cache coherent interface. Data placement and migration become more difficult, and they can be done in various places, e.g. in hardware (e.g. now-discontinued Optane in memory mode), transparently by the OS (at page granularity) or by the runtime system or support library (at page or object granularity), or even by the compiler. If not, the whole zoo of memory types may simply be exposed to the application.
Processing in memory is a general term that covers any form of integration of processing capability into the memory system.[1] It was initially proposed in the 1970s,[2] but it has received renewed interest as a way to avoid the memory wall. There are several approaches for processing in memory, including computation inside the memory array or peripheral circuits, as well as logic layers and dies integrated alongside memory dies within the silicon package. Examples include Micron’s Automata Processor, which adapts the DRAM memory arrays and peripheral circuits for finite automata, UPMEM’s DRAM Processing Units (DPUs), which are embedded next to the DRAM bank, and Samsung’s Function-In-Memory DRAM (FIMDRAM, which) integrates SIMD processors in the memory bank. The multiplicity of approaches represents challenges for OS management (data placement, security, resilience) and the programming environment (translating algorithms to the architecture, as well as debugging and performance analysis).
In-network computing refers to the integration of computational capabilities directly into the network, specifically within network switches and routers of a data centre or HPC system. This approach contrasts with traditional network architectures, where data processing is performed solely at the endpoints, such as servers or client devices. The key idea is to leverage the network hardware itself for certain types of data processing tasks. By doing so, it can reduce the data processing load on servers, decrease network latency, and improve overall system efficiency. This is particularly beneficial for applications involving large-scale data movement, real-time analytics, and distributed computing scenarios where reducing latency and data movement is crucial. In this architecture, network devices are equipped with processing units that can perform a range of functions like data aggregation, filtering, or even more complex operations like machine learning inference, directly on the data as it passes through the network. In-network computing is an emerging field, driven by advancements in networking hardware and the increasing demands of modern applications for faster data processing and reduced latency. It represents a shift in how data networks are traditionally viewed, evolving from mere data conduits to active processing nodes within an IT infrastructure.
Quantum computing was first suggested by Richard Feynmann in 1981 for the simulation of quantum systems. Revolutionary algorithms for prime factorization (Shor’s algorithm, 1994) and unstructured search (Grover’s algorithm, 1996) showed that quantum computing has the potential for exponential speedup for certain algorithms over classical computers. A quantum computer is likely to appear as another kind of accelerator in a heterogeneous system, so quantum computing is related to the topics of this paper. Recent advances have led to impressive quantum computers, taking a number of different approaches. More details are in the article on quantum computing.
 Figure 2 A “Cambrian explosion” in computer architectures, showcasing an array of diverse and innovative chip designs (made by ChatGPT).
Figure 2 A “Cambrian explosion” in computer architectures, showcasing an array of diverse and innovative chip designs (made by ChatGPT).
The programmability challenge
The move from general purpose processors to a diverse set of specialized and heterogeneous systems improves energy efficiency and performance. But it raises software complexity, especially because a single application needs to run well across a range of systems. A key challenge will be to identify and support high-level software abstractions that exploit the full capabilities of the hardware, while abstracting away most of the architectural diversity. The main application code should ideally be platform independent, with an open, clean, stable and dependable interface to the hardware. Previously, for performance-critical code on general purpose processors, this was single-threaded C or C++. But now this is under pressure.
Ideally, the platform-independent part should avoid direct references to specific resources and their availability, and instead provide declarative information that is sufficient to optimise behaviour. A number of different strategies, frameworks and libraries have been proposed, and are under investigation, but none are yet a general solution. OpenCL offers functional portability across heterogeneous platforms, including different types of GPUs and CPUs, but good performance requires the code to be optimized for the architecture. Performance portability, meaning that the same code achieves optimal performance on all platforms, and it is a holy grail in the field. SYCL has provided some promising results in this direction, but its adoption is not very wide and neither all platforms have an optimized backend. Overall, more intelligence is needed in the programming environment, from compilers to runtime systems to performance and debugging tools. One avenue is to explore the use of artificial intelligence techniques, as exemplified by large language models such as ChatGPT-4, to perform the translation from a declarative specification of the problem into an optimized source code or intermediate representation. The progress in related techniques has been spectacular in recent years, so this is an interesting approach. However, special attention should be paid that standardized solutions with open specifications will be used, in order to allow interoperability within the heterogeneous environment and avoid vendor lock-in.
Domain Specific Languages (DSLs) are specialized programming languages designed for a particular application domain. They offer enhanced productivity and ease of use for domain experts, who can focus on domain-relevant aspects and abstract away the complexities of programming. They also reduce the likelihood of certain types of errors and bridge the gap between domain experts and developers, by using terminology and concepts familiar to practitioners in the field. While DSLs are user-friendly for domain experts, there may be a learning curve for developers not familiar with the domain. Also, they may suffer from limited support and community resources, unless they are widely adopted. Integrating DSLs with other systems and languages can also be complex, as they might not easily interact with software written in general-purpose languages. It is beneficial to avoid a proliferation of DSLs by identifying and using common reusable features, leading to a small number of more generic DSLs or DSL frameworks, and/or their integration into more general purpose programming environments. DSLs are most beneficial when the advantages in productivity and performance outweigh the costs and limitations in scope and support.
Task-based programming first appeared in the 1990s and it is already mainstream in high performance computing through its adoption in the OpenMP 3.0 standard in 2008.[3] The tasking models separates the program into (a) a decomposition of a algorithm, in an architecture independent way, into tasks with dependencies, (b) a runtime system, aware of the architecture, which manages scheduling, the choice of execution device and data locality, and (c) implementation of the low-level kernels, which is typically device-specific. It is especially beneficial for asynchronous parallelism and complex system architectures.
Finally, as the general-purpose CPU becomes relegated to a mainly orchestration role, management by the system software and middleware must not become the bottleneck. Such activity must be moved outside the critical path of computation and communication.
Conclusion
Heterogeneous and specialized architectures are not new. They have been consistently featured in the HiPEAC roadmap since the first “HiPEAC vision” in 2007. The end of Dennard scaling has led to a new golden age of computer architecture and a Cambrian explosion of approaches, from GPUs, to neural acceleration, to FPGAs, as well as the integration of processing capabilities into memory and storage. There is as yet no performance portable programming environment that allows a single source codebase to achieve good performance across a range of architectures. There may never be one, but more progress towards this goal is needed.
AUTHORS
Jaume Abella is a researcher in the Computer Sciences Department at Barcelona Supercomputing Center, Spain.
Leonidas Kosmidis is a researcher in the Computer Sciences Department at Barcelona Supercomputing Center, Spain and serves as an Outreach Officer for Khronos’ SYCL SC (Safety Critical) WG.
Thomas Hoberg is technical director at Worldline Labs, Frankfurt, Germany.
Paul Carpenter is a researcher in the Computer Sciences Department at Barcelona Supercomputing Center, Spain.
REFERENCES
[1]: Stanford University, "Genie: the Open, Privacy-Preserving Virtual Assistant," Open Virtual Assistant Lab at Stanford University, [Online]. Available: https://genie.stanford.edu/. [Accessed 29 November 2022].
[2]: T. Vardanega and M. Duranton, "“Guardian Angels” to protect and orchestrate cyber life," HiPEAC Vision 2021, pp. 48-53, https://doi.org/10.5281/zenodo.4719375, January 2021.
[3]: T. Vardanega, M. Duranton, K. De Bosschere and H. Munk, "Past, present and future of the web: A HiPEAC Vision," 2019. [Online]. Available: https://www.hipeac.net/media/public/files/46/7/HiPEAC-2019-Comic-Book.pdf.
[4]: "Stable Diffusion on GitHub," [Online]. Available: https://github.com/CompVis/stable- diffusion. [Accessed 24 November 2022].
[5]: "WebAssembly," [Online]. Available: https:// webassembly.org.
[6]: "Ballerina," [Online]. Available: https://ballerina.io.
[7]: R. P. Feynman, "Simulating physics with computers,," Int. J. Theor. Physics, pp. 21, 467-488, 1982.
[8]: J. Preskill, "Quantum Computing in the NISQ era and beyond," Quantum, p. 79, 2018.
[9]: "NUKIB - Tsjech National Cyber and Information Security Agency," [Online]. Available: https://nukib.cz/cs/infoservis/aktuality/1984-nukib-pripravil-podpurne-materialy-pro-ochranu-pred-hrozbou-v-podobe-kvantovych-pocitacu/.
[10]: T. Attema, J. Diogo Duarte, V. Dunning, M. Lequesne, W. van der Schoot and M. Stevens, "Het PQC-migratie handboek (in Dutch)," 2023.
[11]: "Post-Quantum Cryptography - Setting the Future Security Standards," [Online]. Available: https://www.nxp.com/applications/enabling-technologies/security/post-quantum-cryptography:POST-QUANTUM-CRYPTOGRAPHY.
[12]: A. Singh, K. Dev, H. Siljak, H. Joshi and M. Magarini, "Quantum Internet—Applications, Functionalities, Enabling Technologies, Challenges, and Research Directions," IEEE Communications Surveys & Tutorials, pp. 2218-2247, 2021.
[13]: B. Kantsepolsky, I. Aviv, R. Weitzfeld and E. Bordo, "Exploring Quantum Sensing Potential for Systems Applications," IEEE Access, pp. 31569-31582, 2023.
ETP4HPC, https://www.etp4hpc.eu/pujades/files/ETP4HPC_WP_Processing-In-Memory_FINAL.pdf ↩︎
H. S. Stone, “A Logic-in-Memory Computer,” IEEE Transactions on Computers, vol. 19, 1970. ↩︎
https://www.etp4hpc.eu/pujades/files/ETP4HPC_WP_Task-based-PP_FINAL.pdf ↩︎